
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- 빅 데이터
- Deep learning
- 김양재
- Artificial Intelligence
- 우리들교회
- R
- 통계
- 딥러닝
- Statistics
- 김양재 목사님
- 확률
- No SQL
- Big Data
- 빅데이터
- nodeJS
- WebGL
- 데이터 과학
- node.js
- MongoDB
- 김양재 목사
- openCV
- 빅데이타
- 빅 데이타
- 몽고디비
- Machine Learning
- 주일설교
- probability
- data science
- c++
- Today
- Total
목록Statistics (48)
Scientific Computing & Data Science
[Definition][\(\chi\)-제곱 분포] \( f(x;k) = \begin{cases} \displaystyle{\frac{x^{\frac{k}{2}-1}e^{-\frac{x}{2}}} {2^{\frac{k}{2}}\Gamma(\frac{k}{2})} }, \ \mathrm{if} \ x > 0 \\ 0, \ \mathrm{if} \ x \le 0 \end{cases} \) \(\Gamma(\frac{k}{2})\): 파라미터 k에 대한 Closed Form을 갖는 감마 함수x: 랜덤 변수,k: 정수 파라미터 [누적 \(\chi\)-제곱 분포] \( F(x;k) = \displaystyle{ \frac{ \Gamma \begin{pmatrix} \displaystyle{\frac{x}{2}, ..
 [Data Science / Posts] 머신러닝, 데이터과학, AI, 딥러닝, 통계학 사이의 차이점
[Data Science / Posts] 머신러닝, 데이터과학, AI, 딥러닝, 통계학 사이의 차이점
* 이 글은 Data Science Central의 "Difference between Machine Learning, Data Science, AI, Deep Learning, and Statistics"을 번역한 것이다. 이번 글에서는 데이터 과학자의 다양한 역할과 머신러닝, 딥 러닝, AI, 통계학, IoT, 오퍼레이션 리서치, 응용 수학 등과 같은 관련 분야와 데이터 과학이 어떻게 다른지 공통점은 무엇인지 기술하고자 한다.데이터 과학은 넓은 분야를 포괄하는 만큼, 어떤 사업 분야에서도 마주칠 수 있는 데이터 과학자의 다양한 유형에 대해 살펴보기록 한다: 각자는 자신이 미처 몰랐던 스스로가 데이터 과학자임을 깨닫게 될 수도 있다.다른 과학 분야의 소양과 마찬가지로, 데이터 과학자들은 관련 소양으로부..
 [Artificial Intelligence / Machine Learning] Naive Bayes Spam Filter Part 2.
[Artificial Intelligence / Machine Learning] Naive Bayes Spam Filter Part 2.
Written by Geol Choi | Nov. 12, 2016 이전 글(Naive Bayes Spam Filter Part 1.)에서 Naive Bayes에 대한 이론을 다뤘습니다. 이번 글에서는 이론을 바탕으로 휴대폰의 SMS 데이터의 Spam Filter를 작성해 보도록 하겠습니다. 일반적인 데이터 분석 프로세스는, (1) 문제 정의(2) 데이터 획득(3) 데이터 클린업(4) 데이터 정규화(5) 데이터 변형 및 가공(6) 데이터 탐구 기반 통계(7) 데이터 탐구 기반 시각화(8) 예측 모델(9) 모델 평가(10) 결과에 대한 시각화 및 해석(11) 솔루션 배포 인데, Machine Learning에 의한 결과 도출도 이 순서와 크게 다르지 않으며, 전체적인 순서는 다음 그림과 같습니다. 1. 데이..
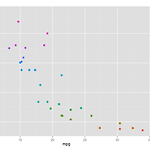 [Data Mining with R] R / Simple Linear Regression - Part 1.
[Data Mining with R] R / Simple Linear Regression - Part 1.
by Geol Choi | November 23, 2014 이번 글에서는 Linear Regression에 대한 기초 통계 이론에 대한 소개와 이에 대한 R 프로그래밍에 대해 알아보기로 한다. Linear Regression은 간단하게 말해, 관찰된 데이터들의 변수들 간 관계를 1차원적인 Graph로 표현(이를 fitting이라고 함)하는 것이다. Linear Regression은 통계학의 역사관점에서 볼 때, 특정 변수가 다른 변수와 어떤 상관관계인지를 알아보기 위한 수단으로 발전해 왔다. 데이터를 관찰하여 이에 대한 모델을 세우고 이 모델을 통해 데이터에 대한 예측을 하고자 하는 것이 목표이며, 더 나아가 이에 대한 신뢰도를 어떻게 평가할 수 있는가가 이 이론에 대한 거의 전부라고 할 수 있다. 물론..
 [Data Mining with R Programming] 개요
[Data Mining with R Programming] 개요
'데이터 마이닝'이란 금을 채광(Gold Mining)하는 것처럼, 획득된 데이터로부터 의미있거나 가치있는 정보를 발견하는 일을 의미한다. 이러한 활동을 통해 기업들은 소비자들이 원하는 것이 무엇인지 발견하여 마켓팅으로 활용하거나 새로운 비즈니스의 기회를 모색할 수도 있다. 또한 각종 정부기관들은 재난사고를 미리 예측하여 사고를 예방하거나 여론을 파악하는데 활용할 수도 있다.데이터 마이닝은 데이터로부터 가치를 발견한다는 점에서 단순 데이터 분석과는 차별된다. 단, 데이터 마이닝을 위해서는 획득할 수 있는 데이터의 범주가 다양할 수록 좋다. 왜냐하면 데이터의 범주가 다양할 수록 다양한 의미를 발견할 가능성이 높아지기 때문이다.데이터에 대해 많은 의존을 하는 스포츠 중의 하나인 야구를 예로 들어보자. 우리나..
 [Data Analysis] 개요 / 데이터 분석 관련 분야
[Data Analysis] 개요 / 데이터 분석 관련 분야
"데이터 분석"이란 가공되지 않은 데이터를 정렬하고 조직화하여 과거를 설명하고 미래를 예측할 수 있는 방법을 세우는 과정이다. 데이터 분석은 단순한 숫자에 관한 것이 아니며, 질문을 세우거나 질문을 하는 것, 설명 방식에 대한 개발을 하는 것, 가설을 검증하는 것에 관한 것이다. 데이터 분석은 다중의 분야를 융합하는 것으로써, 해당 분야는 컴퓨터 과학(Computer Science), 인공 지능(Artificial Intelligence), 기계 학습(Machine Learning), 통계와 수학(Statistics & Mathematics), 지식 도메인(Knowledge Domain)이다.컴퓨터 과학컴퓨터 과학은 데이터 분석과 분석된 데이터의 설명을 위한 가시화에 관련된 도구를 제공한다. 데이터 분석..
이번 글에서는 어떤 분포의 파라미터에 대해 추정하는 방법을 알아보도록 하겠다. 예를 들어, 실험자가 데이터 세트를 얻었으며 이 데이터 세트를 베타 분포라고 가정할 경우 베타 분포의 파라미터를 어떻게 추정할 것인가에 대한 물음이다.이를 해결하는 방법은 두 가지가 있는데, 하나는 모멘트 방법(Moment of Moments)이며 다른 하나는 최대 가능성 추정(Maximum Likelyhood Estimation; MLE)이다. [Definition] 파라미터 한 개에 대한 모멘트 방법 점 추정만약 데이터 세트가 한 개의 미지의 파라미터 \(\theta\)에 의존하는 확률분포로부터 얻은 데이터 \(x_1 , ... , x_n\)이라면, 파라미터의 모멘트 방법 점 추정 \(\hat{\theta}\)은 다음 방정..
[Def.] 표본 비율(Sample Proportion)만약 \(X \sim B(n,p)\)이라면 표본 비율 \(\hat{p}=X/n\)은 근사 분산 \(\hat{p} \sim N \displaystyle{\begin{pmatrix}p, \frac{p(1-p)}{n} \end{pmatrix}}\) 을 갖는다. [Proof]\(\mathrm{Var}(\hat{p}) = \mathrm{Var}\displaystyle{\frac{X}{n}} = \displaystyle{\frac{1}{n^2}np(1-p) = \displaystyle{\frac{p(1-p)}{n}}}\)[Def.] 표준오차(Standard Error)표준오차 s.e.는 \(\hat{p}\)의 표준편차이며 \(\mathrm{s.e.}(\hat{..
편향 점 추정 (Unbiased Point Estimates)Definition 파라미터 \(\theta\)에 대한 점추정 \(\hat{\theta}\)는 \( \mathrm{E}(\hat{\theta}) = \theta \)인 경우 "비편향(unbiased)"라고 한다. "비편향"은 점 추정에 대한 좋은 특성이라고 할 수 있다. 만약 점 추정이 비편향이 아니라면, 이를 "편향(biased)"이라고 하며 다음과 같이 정의된다: \( \mathrm{bias} = \mathrm{E}(\hat{\theta}) - \theta \) 다른 조건이 동일한 경우, 점 추정의 보다 작은 절대값의 편향성이 더 좋은 것이다.성공 확률의 점 추정Definition 라고 할 때 는 성공 확률 p의 비편향 점 추정이다. Pro..
 [Data Science / Statistics] Statistical Estimation & Sampling Distributions - Point Estimation
[Data Science / Statistics] Statistical Estimation & Sampling Distributions - Point Estimation
[Definition] 파라미터(Parameters)통계적 추론에 있어, 파라미터란 어떠한 측정량, \(\theta\)를 지칭하는데 사용된다. \(\theta\)는 알려지지 않은 확률 분포의 속성이다. 예를 들어, \(\theta\)는 확률 분포의 평균, 분산, 또는 Quantile 등이 될 수 있다. 파라미터는 미지의 값이며, 통계적 추론의 한 가지 목표는 이러한 파라미터를 추정하는 것이다.[Definition] 통계량(Statistics)통계적 추론에 있어, 통계량이란 표본의 속성인 측정량을 지칭하는데 사용된다. 예를 들어, 표본 평균, 표본 분산 또는 표본 퀀타일 등을 일컫는다. 통계량은 관찰된 값이 관찰된 데이터 값의 집합으로부터 계산되는 랜덤 변수이다. 통계량은 미지의 파라미터를 추정하는데 사용..