
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Deep learning
- c++
- 몽고디비
- 김양재 목사님
- nodeJS
- 빅 데이터
- 우리들교회
- 빅 데이타
- R
- MongoDB
- openCV
- 데이터 과학
- 빅데이타
- Machine Learning
- 김양재
- Statistics
- probability
- 빅데이터
- Big Data
- 김양재 목사
- 주일설교
- 딥러닝
- Artificial Intelligence
- 인공지능
- WebGL
- 통계
- node.js
- 확률
- data science
- No SQL
- Today
- Total
목록Data Science (257)
Scientific Computing & Data Science
 [Data Science] 데이터 과학자의 역할
[Data Science] 데이터 과학자의 역할
Written by CINEMA4D * 데이터 과학의 과학적 접근 방법에 대한 절차질문을 한다.백그라운드 리서치(Background Research)를 수행한다.가설을 세운다.실험을 통해 가설을 테스트한다.데이터를 분석하고 결론을 도출한다.결과에 대한 토의를 한다.
Written by CINEMA4D데이터 과학에 있어 데이터를 처리하는 순서는 다음 그림과 같다: [실세계]각종 포털사이트, 온/오프라인 쇼핑몰, Facebook, Google+, Twitter와 같은 SNS 등 데이터를 수집할 수 있는 모든 데이터 원천을 의미한다. [미가공 데이터]실세계로부터 얻어진 데이터는 가공되지 않은 형태의 "있는 그대로의 데이터(Raw Data)"로 존재한다. 이것은 로그 파일, 이메일, 동영상, 음성 등 다양한 비정형 데이터로 존재할 가능성이 높으며 정형화 된 형태일지라도 데이터가 유실될 경우도 많다. [데이터 처리]미가공 데이터는 R, Python, Ruby 등과 같은 데이터 처리 도구를 통하여 처리되고 SQL, NoSQL 등과 같은 데이터 쿼리 언어를 통해 데이터를 저장한..
빅 데이터는 오늘날 모호한 허술하게 사용되는 모호한 용어이다. 간단히 표현하여 캐치프레이즈는 세 가지를 담고 있다. 첫째, 빅 데이터는 기술의 집약체이다. 둘째, 측정에 있어 잠재적 혁명이다. 셋째, 미래에 이루게 될 결정방법에 대한 관점 또는 철학이다. - Steve Lohr The New York Times[빅 데이터에 대하여 재고할 세 가지] 1. "빅"은 움직이는 목표이다.빅 데이터를 1 페타바이트와 같은 크기 이상의 데이터로 규정하는 하는 것은 의미없다.왜냐하면 크기에 대한 절대적인 조건이 있는 것처럼 생각되기 때문이다.크기가 도전적인 문제가 될 때에만 "빅"이라고 칭할 수 있을 것이다.따라서 "빅"의 개념은 데이터의 크기가 기존의 계산 도구가 감당할 수 있는 한계(메모리, 스토리지, 복잡도, ..
In R console copy & paste the below:if (!require("devtools")) install.packages("devtools") devtools::install_github("rstudio/shinyapps")
Setting up Shiny Server on Amazon’s Elastic Compute Cloud (EC2) can be a bit of a process if you’re unfamiliar with Linux system administration. Thankfully, we’ve done all the hard work for you! If you’re looking to get Shiny Server running in EC2 without delay, just boot up an instance of our public Amazon Machine Image (AMI): ami-e2a3358b named “ShinyServer.”If you’re interested in the details..
 [Data Visualisation] rCharts / rPlot
[Data Visualisation] rCharts / rPlot
이번 글에서는 R의 데이터 시각화 패키지인 rCharts를 이용하여 데이터를 시각화하는 방법에 대하여 알아보도록 하겠다. 첫번째 순서로 rPlot을 이용하여 scatter plot을 그려보도록 한다. [데이터 가공] 우선 공공데이터 포털(www.data.go.kr)로부터 데이터 시각화를 위한 테스트 데이터를 얻는다. 얻고자 하는 데이터는 "국가별 경제지표 중 2010년 이후 지역별 수출선행지수 분기별 추이"이다. 직접 사이트를 방문하여 데이터를 다운로드하여도 되고 다음 링크를 클릭하여 다운로드 해도 된다. 데이터를 살펴보면 다음과 같다:,2012 Q1,2012 Q2,2012 Q3,2012 Q4,2013 Q1,2013 Q2,2013 Q3,2013 Q4,2014 Q1,2014Q2,2014Q3,2014Q4 유..
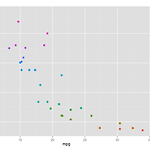
by Geol Choi | December 14, 2014 이번 글에서는 기울기 \(\beta_{1}\)에 대한 추정에 대하여 알아보도록 하자. 우선 이론적 배경을 살펴보도록 하고 R 코드를 이용하여 예제를 통해 이해하도록 한다.Theoretical Background기울기 \(\beta_{1}\)은 실험자에게 특별한 관심 대상인데, 실험 값 x와 이에 대한 결과 값 y의 상관성 지표를 나타내기 때문이다. 기울기 값에 대한 신뢰 구간(confidence interval)을 계산하는 것과 기울기 값이 특정 값을 값는 것에 대한 가설을 테스트하는 것은 매우 유용하다. \(\beta_{1}\)을 실험 데이터에 대한 알려지지 않은 참값(True Value)라고 하고 \(\hat{\beta}_1\)을 데이터 세트..
 [Data Mining with R] R / Simple Linear Regression - Part 1.
[Data Mining with R] R / Simple Linear Regression - Part 1.
by Geol Choi | November 23, 2014 이번 글에서는 Linear Regression에 대한 기초 통계 이론에 대한 소개와 이에 대한 R 프로그래밍에 대해 알아보기로 한다. Linear Regression은 간단하게 말해, 관찰된 데이터들의 변수들 간 관계를 1차원적인 Graph로 표현(이를 fitting이라고 함)하는 것이다. Linear Regression은 통계학의 역사관점에서 볼 때, 특정 변수가 다른 변수와 어떤 상관관계인지를 알아보기 위한 수단으로 발전해 왔다. 데이터를 관찰하여 이에 대한 모델을 세우고 이 모델을 통해 데이터에 대한 예측을 하고자 하는 것이 목표이며, 더 나아가 이에 대한 신뢰도를 어떻게 평가할 수 있는가가 이 이론에 대한 거의 전부라고 할 수 있다. 물론..
예전 글에서 R과 MongoDB 연동에 대해 다룬 적이 있다.이번 글에서는 로컬호스트의 MongoDB가 아닌 MongoDB의 클라우드 호스팅인 MongoLab과 R을 연동하는 방법에 대하여 알아보도록 하자. 우선 MongoLab에서 만든 Database를 하나 만들고 데이터를 입력한다. 설명을 위해 다음을 가정한다:- Database Name: myDB- DB User: gchoi- Password: 1234 위와 같이 DB를 만들면 MongoLab에서 다음과 유사한 형태의 URI Standard를 제시할 것이다:mongodb://:@ds047950.mongolab.com:47950/myDB 이제 Shell에서 다음과 같이 입력하여 MongoLab과 연결한다:$ mongo ds047950.mongolab..
이번 글에서는 Reactive Output에 대하여 알아보기로 한다. 백번 글로 설명하기 보다는 한 번 예제로 설명하는 것이 효과적이기 때문에 동일한 application에 대하여 하나는 Reactive Output을 적용하지 않은 것과 다른 하나는 적용된 것을 비교하여 설명하기로 한다.Application은 Slider Input으로부터 숫자를 입력받아 해당 숫자에 대한 Normal Distribution(N ~ (0,12))에 대한 랜덤 데이터를 생성하고 이들에 대한 Plot을 출력하는 것이다. 1. Without Reactive Output[Results] [ui.R] shinyUI( pageWithSidebar( headerPanel("Reactive Example - Without Reactiv..