
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Artificial Intelligence
- No SQL
- WebGL
- 확률
- R
- 데이터 과학
- data science
- 주일설교
- nodeJS
- 몽고디비
- MongoDB
- probability
- Machine Learning
- 우리들교회
- Deep learning
- 딥러닝
- Big Data
- openCV
- 통계
- 김양재 목사
- 빅 데이터
- 빅데이터
- c++
- 김양재 목사님
- 인공지능
- 김양재
- 빅데이타
- node.js
- Statistics
- 빅 데이타
- Today
- Total
Scientific Computing & Data Science
[Data Science] 빅데이터를 위한 맵 리듀스 활용법 본문
맵 리듀스는 빅데이터에 있어 이상적인 소프트웨어 프레임웍이다. 왜냐하면 프로세서 분산 그룹 상에서 방대한 양의 비정형(unstructured) 데이터를 병렬로 처리할 수 있는 프로그램을 개발할 수 있는 도구이기 때문이다.
빅데이터를 위한 맵 함수
맵(map) 함수는 다년간 많은 함수형 프로그래밍 언어의 일부였다. 맵은 데이터 요소의 처리 항목에 있어 핵심 기술로 새로운 활력을 불어 넣었다.
함수형 언어의 운용자들은 데이터의 구조를 변경하지 않았다; 이들은 결과 출력을 위해 새로운 데이터 구조를 만들어냈다. 본래의 데이터 자체 또한 변경되지 않았다. 따라서 맵 함수를 무사히(?) 사용할 수 있는데 이는 여러분의 소중한 데이터에 어떤 해도 가하지 않을 것이기 때문이다.
함수형 프로그래밍의 또다른 장점은 데이터의 이동이나 흐름에 대한 명확한 관리가 필요 없다는 것이다. 프로그래머가 데이머 출력 및 배치에 대한 명시적 관리에서 자유로울 수 있다는 것이다. 결론적으로 말하면, 데이터 운용의 순서가 규정되지 않는다.
솔루션을 달성하는 한 가지 방법은 입력 데이터를 규정하고 항목을 생성하는 것이다:
mylist = ("all counties in the us that participated in the most recent general election")맵 함수를 이용하여 함수 howManyPeople를 생성한다. 이는 50,000명 이상이 거주하는 카운티(자치주, county)들만을 선택한다.
map howManyPeople (mylist) = [ howManyPeople "county 1"; howManyPeople "county 2"; howManyPeople "county 3"; howManyPeople "county 4"; . . . ]이제 50,000 이상의 인구가 거주하는 모든 카운티의 새로운 항목을 생성한다:
(no, county 1; yes, county 2; no, county 3; yes, county 4; ?, county nnn)함수는 원본 항목에 대한 변경 없이 실행된다. 게다가 출력 항목의 각 요소가 yes 또는 noattached를 갖는 입력 항목의 각 해당 요소에 대응된다. 만약 카운티가 50,000명 이상의 조건에 부합될 경우, 맵 함수는 yes로 인식된다. 반대의 경우 no로 지정된다.
빅데이터를 위한 리듀스 함수 추가
맵 함수와 마찬가지로, 리듀스(reduce)는 수년간 함수 프로그래밍 언어의 특징이 되어 왔다. 리듀스 함수는 맵 함수의 출력을 받아들이고 프로그래머가 원하는 방식으로 항목을 "축소"한다.
함수를 축소에 필요한 첫번째 단계는 "축적자(accumulator)"라고 불리우는 것에 값을 위치시키는 것이며, 이는 초기값을 갖는다. 축적자에 초기값이 저장된 후, 리듀스 함수는 항목의 각 요소를 처리하고 항목 상의 오퍼레이션을 수행한다.
항목의 맨 끝단에서, 리듀스 함수는 출력 항목에 수행되어야 하는 오퍼레이션에 기반하는 값을 반환한다.
민주당 후보가 우세적인 카운티를 구분하고자 한다고 가정해 보자. howManyPeople 맵 함수가 입력 항목의 각 요소를 바라보고 있으며 50,000명 이상(yes)의 카운티 출력 항목과 50,000명 이하(no)의 카운티 출력 항목을 생성했음을 상기해 보자.
howManyPeople 맵 함수가 실행되면, 이제 남은 다음 출력 항목이다:
(no, county 1; yes, county 2; no, county 3; yes, county 4; ?, county nnn)
이것은 이제 리듀스 함수에 대한 입력이 된다. 입력은 다음과 같다:
countylist = (no, county 1; yes, county 2; no, county 3; yes, county 4; ?, county nnn)
reduce isDemocrat (countylist)
리듀스 함수는 항목의 각 요소를 처리하고 민주당이 우세한 50,000인 이상의 인구가 거주하는 모든 카운티를 반환한다.
빅데이터 맵과 리듀스 합치기
때로는 출력 항목을 생성하는 것만으로도 충분하다. 마찬가지로, 때때로 각 요소에 대한 오퍼레이션을 수행하는 것만으로도 충분할 때가 있다. 대부분의 경우, 여러분이 원하는 것은 많은 양의 입력 데이터를 훑고 데이터로부터 특정 요소를 선별하고 해당 데이터로부터 어떤 값을 연산하는 것이다.
입력 항목의 변경을 원치 않는다면 새로운 가정과 새로운 데이터로 다른 방법을 사용할 수 있다.
소프트웨어 개발자들은 알고리즘에 입각하여 어플리케이션을 설계한다. 알고리즘은 전체 목표를 향한 서비스에서 발생할 만한 일련의 과정에 불과하다. 이는 다음과 같은 절차와 유사하다:
큰 수 또는 큰 데이터 또는 레코드로 시작한다.
데이터에 걸쳐 반복한다.
맵 함수를 이용하여 흥미로운 결과를 도출하고 출력 항목을 생성한다.
출력 항목을 조직화하여 프로세스를 최적화한다.
리듀스 함수를 이용하여 결과 세트를 계산한다.
최종 출력을 생성한다.
프로그래머는 이러한 접근법을 이용하여 모든 종류의 어플리케이션을 개발하지만, 이러한 관점에 대한 예는 매우 단순한 것이어서 맵 리듀스의 실제 값은 명확하지 않을 수도 있다. 극도로 많은 양의 입력 데이터를 갖는다면 어떤 일이 벌어질 것인가? 테라바이트의 데이터에 대해서도 동일한 알고리즘을 적용할 수 있을 것인가? 다행히도 좋은 소식은 "그럴 수 있다"이다.
모든 오퍼레이션은 독립적인 것처럼 보인다. 이는 실제로 그렇기 때문이다. 맵 리듀스의 진정한 능력은 분리하고 정복(divide and conquer)할 수 있다는 데 있다. 매우 큰 문제를 잘게 그리고 다루기 좋은 덩어리로 쪼개고 각 덩어리를 독립적으로 운용한 후 최종적으로 이들을 합치는 것이다. 더군다나, 맵 함수는 교환법칙이 성립한다. 다시 말해 함수가 실행되는 순서는 아무런 문제가 되지 않는다.
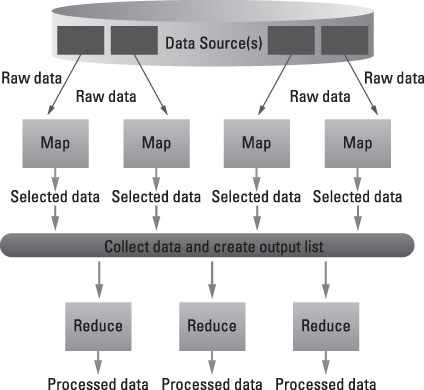
따라서 맵 리듀스는 네트워크 상의 서로 다른 머쉰 상에서 실행 가능하다. 맵 리듀스는 내부 또는 외부의 다중 데이터 소스로부터 데이터를 뽑을 수 있다. 맵 리듀스는 모든 데이터가 동일한 문제 해결을 위한 유일한 방법을 생성하는 식으로 동작을 기록한다. 이 방식은 모든 분산 태스크의 종료 시점에서 모든 출력을 취합하는데 이용되기도 한다.
'Data Science > Posts' 카테고리의 다른 글
| [Data Science] 빅데이터 가상화의 중요성 (0) | 2014.01.08 |
|---|---|
| [Data Science] 빅데이터 분석법은 '보험 사기'를 어떻게 식별할 것인가? (0) | 2014.01.07 |
| [Data Science] 하둡을 이용한 데이터 관리: Hadoop과 Map Reduce (0) | 2014.01.07 |
| [Data Science] 빅데이터 분석, 어떻게 할 것인가 (0) | 2014.01.07 |
| [Data Science] 빅데이터의 10가지 핫 트렌드 (0) | 2014.01.06 |