
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Statistics
- R
- c++
- 김양재 목사님
- No SQL
- 데이터 과학
- Artificial Intelligence
- WebGL
- 빅데이터
- 인공지능
- 빅데이타
- probability
- node.js
- Machine Learning
- 빅 데이터
- nodeJS
- Deep learning
- 통계
- 우리들교회
- 주일설교
- 김양재 목사
- Big Data
- 빅 데이타
- 딥러닝
- MongoDB
- 확률
- 몽고디비
- openCV
- data science
- 김양재
- Today
- Total
Scientific Computing & Data Science
[Artificial Intelligence / Posts] 핵심 머신러닝 용어 본문
[Artificial Intelligence / Posts] 핵심 머신러닝 용어
cinema4dr12 2017. 3. 19. 23:361. 머신러닝 (Machine Learning; ML)
Mitchell에 따르면, ML은 "경험에 의해 자동으로 개선되는 컴퓨터 프로그램을 어떻게 구현할 것인가"와 관련이 깊다. ML은 자연적으로 여러 분야에 걸쳐있으며, 컴퓨터 과학, 통계, 인공지능 및 기타 분야의 다양한 기술을 도입한다. ML 연구의 주요 성과물은 경험으로부터 자동 개선을 가능하게 하는 알고리즘, 컴퓨터 비전, 인공지능, 데이터 마이닝(Data Mining)과 같은 분야 적용할 수 있는 알고리즘 등이다.
2. 분류 (Classification)
분류는 데이터를 정해진 카테고리에 지정하는 모델을 구축하는 것과 관련이 깊다. 이 모델들은 알고리즘이 학습할 수 있도록 미리 라벨링된 학습 데이터세트를 입력하여 구축된다. 그리고나서 그 모델을 분류가 보류된 다양한 데이터세트를 입력하여 사용하며, 학습 데이터세트로부터 학습한 것을 근거로 분류에 대한 예측을 할 수 있도록 한다. 잘 알려진 분류 방법에는 결정 트리 및 서포트 벡터 머신 등이 있다. 이러한 유형의 알고리즘이 명시적 클래시 라벨링을 요구하는 것처럼, 분류는 지도 학습(Supervised Learning)의 한 형태이다.
3. 회귀 (Regression)
회귀는 분류와 매우 관련이 깊다.
분류가 이산 클래스를 예측하는 것과 연관이 있는 반면, 회귀는 예측할 "클래스"가 연속적인 숫자값으로 구성되는 것에 대해 적용된다. 선형 회귀는 회귀 방법의 예이다.
4. 클러스터링(Clustering)
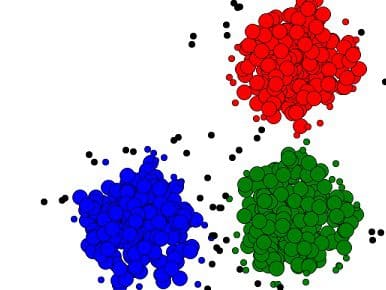
클러스터링은 사전 라벨링된 클래스를 포함하지 않는 데이터 또는 아예 클래스 속성이 없는 데이터를 분석하는데 사용된다. Han, Kamber & Pei가 언급한 바와 같이, 데이터 인스턴스는 "클래스 내 유사성을 최대화하고 클래스 간 유사성을 최소화"하는 개념을 이용하여 그룹화된다. 이 개념은, 서로 훨씬 덜 유사한 그룹화 되지 않은 인스턴스와는 달리, 매우 유사한 인스턴스를 식별하고 그룹화하는 클러스터링 알고리즘으로 해석된다. k-means 클러스터링은 아마도 가장 잘 알려진 클러스터링 알고리즘의 예이다. 클러스터링이 인스턴스 클래스를 사전에 라벨링하는 것을 요구하지 않는 것처럼, k-means는 비지도 학습의 한 형태이며, 예제를 통해 학습하는 것이 아닌 데이터의 관찰에 의해 학습하는 것을 의미한다.
5. 연계 (Association)
시장 바구니 분석을 소개함으로 연계를 가장 잘 설명할 수 있다. 시장 바구니 분석은 특정 쇼핑객이 온라인 쇼핑이든 오프라인 쇼핑이든 시장 바구니에 담은 다양한 아이템들의 연계에 대한 식별을 시도하고, 비교를 위한 신뢰도 측정을 한다. 이 값은 교차 마켓팅 및 고객 행동 분석에 있다. 연계는 시장 바구니 분석의 일반화이며 모든 속성이 연계를 통해 예측된다는 것을 제외하면 분류 문제와 유사하다. Apriori는 연계 알고리즘의 가장 잘 알려진 예만큼 성공적이다. 연계는 비지도 학습의 또다른 예이다.
6. 결정 트리 (Decision Trees)
결정 트리는 하향식이며, 반복적이며, 분할정복(Divide-and-conquer) 분류자(Classifier)이다. 결정 트리는 일반적으로 다음과 같은 2개의 메인 태스크로 구성된다: 트리 유도(Induction)과 트리 프루닝(Pruning). 트리 유도는 사전에 분류된 인스턴스를 입력으로 취하는 작업인데, 모든 학습 인스턴스가 분류될 때까지 어떠한 속성을 분류자로 삼을 것인지 결정하고, 데이터세트 상에서 쪼개고, 분리 결과 데이터세트 상에서 반복을 한다. 트리는 구성하는 동안, 목표는 가능한 한 순수한 자식 노드를 생성하는 속성을 통해 분할하는 것인데, 이는 데이터세트 내에서 모든 인스턴스를 분류할 목적으로 생성해야 하는 최소의 분리 기준을 유지하도록 하기 위함이다. 이 순수성이라는 것은, 정보 개념으로 측정되는데, 이전에 보이지 않았던 인스턴스가 적절하게 분류될 수 있도록 이에 대해 얼마만큼 알 필요가 있는지와 관련이 있다.
완전한 결정 트리 모델은 과도하게 복잡하고, 불필요한 구조를 포함하며 핵석하기 어려울 수 있다. 트리 프루닝(Pruning)은 결정 트리를 더욱 효율적으로, 보다 가독성이 높고 정확도를 높일 수 있도록 결정 트리로부터 불필요한 구조를 제거하는 과정이다. 정확도 개선은 프루닝의 과도적합을 감소시키는 능력에 따른다.
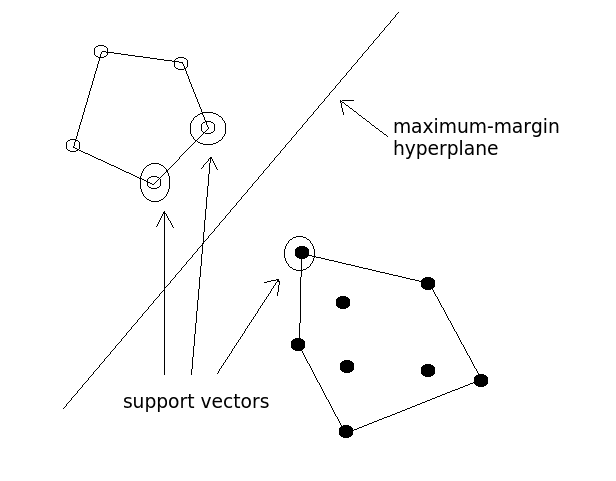
7. 서포트 벡터 머신 (Support Vector Machines; SVM)
SVM은 선형 및 비선형 데이터 모두를 분류할 수 있는 능력을 갖추고 있다. SVM은 학습 데이터세트를 보다 고차원으로 변형함으로 동작하며, 여기서 고차원이란 클래스 간 최적의 경계(또는 경계들)를 탐색하는 것을 의미한다. SVM에서 이러한 경계들은 초평면(Hyperplanes)으로 불리우는데, 서포트 벡테의 위치, 경계를 가장 잘 나누는 인스터스들, 이들의 마진으로 정의되거나, 초평면과 이 평면의 서포트 벡터 간의 최단 거리로 정의되는 초평면에 평행한 선들로 정의되기도 한다.
SVM 아이디어의 강점은, 충분히 큰 차원으로 2개의 클래스를 구분하는 초평면은 항상 존재하여 데이터세트의 멤버 클래스를 설명할 수 있다는 것이다. 충분한 반복회수를 통해 초평면은 n-차원 공간의 모든 클래스들을 분리할 수 있게 된다.
8. 신경망 (Neural Networks)
신경망은, 실제 뇌의 기능을 모사하는지에 대해서는 논란이 있음에도, 생물학적 뇌에 영감을 받은 알고리즘이며, 생물학적 뇌를 모델링했다는 것은 명백한 오류이다. 신경망은 개념적으로 연결된 수많은 인공 신경들로 구성되어 있으며, 이들은 서로 데이터를 주고받고 관련 가중치들(Weights)은 네트워크의 경험에 근거하여 튜닝된다.
뉴런들(신경)은, 만약 이들의 관련 가중치들의 조합과 이들에게 공급된 데이터 값이 조건에 충족된다면, 활성화 임계값이 다음 뉴런에 전달되도록 한다; 이렇게 활성화 된 뉴런의 조합은 "학습"으로 이루어진다.
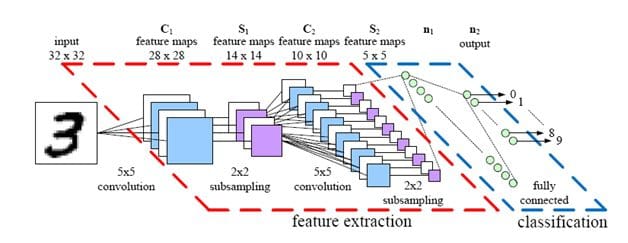
9. 딥러닝 (Deep Learning)
딥러닝은, 최근 온라인 상 연구들 중 극적인 증가 이전에 존재했음에도, 상대적으로 새로운 용어이다. 다양한 분야에서 놀라운 성공을 이룬 덕분에 딥러닝은 학계와 산업계에서 호황을 누리고 있다. 딥러닝은 문제를 해결하기 위해 심층인경망 - 즉, 뉴런을 갖는 다중의 은닉 레이어를 포함하는 신경망 구조 - 기술을 적용하는 과정이다. 딥러닝은 데이터 마이닝과 같이 머신러닝 알고리즘의 한 종류인 심층 신경망 구조를 도입한 프로세스이다.
10. 강화학습 (Reinforcement Learning)
Bishop은 단 한 문장으로 강화학습을 잘 설명하였다: "강화학습은 보상을 최대화하기 위해 주어진 상황에서 적절한 행동을 찾는 문제와 관려이 있다." 강화학습 알고리즘은 명확한 목표가 주어지지 않는다. 대신, 시행착오에 의해 최적의 목표를 학습하도록 되어 있다.
고전 비디오 게임 마리오 브라더스를 생각해 보자: 강화학습 알고리즘은 시행착오를 통해 게임에서 특정 움직임과 버튼을 눌러 플레이어의 위치를 이동시키며, 시행착오는 게임 플레이의 최적 상태를 얻는 것을 목표로 한다.
11. (k-fold) 교차검증 (Cross-validation)
교차 검증은 데이터세트를 k개의 그룹으로 분할하고 (k - 1)개의 그룹에 대해 학습하고 나머지 k번째 세그먼트를 테스트를 위해 활용하는 결정론적 방법론이다. 이 과정은 k번을 반복하는데, 각각의 예측 에러 결과는 하나의 통합된 모델로 조합되고 평균화된다. 이는 가능한 한 가장 정확한 예측 모델을 생성하는 목표를 갖는 가변성을 제공한다.
12. 베이지언 (Bayesian)
확률에 대해 이야기할 때, 다음과 같이 2개의 주요 학파가 있다: 고전학파 또는 빈도학파(Frequentist).
확률 해석은 빈도와 랜덤 사건으로 확률을 바라본다. 이와는 다소 대조적으로, 확률에 대한 베이지언 학파의 관점은 불확실성을 정량화하는 것을 목표로 하고 추가적인 증거를 활용가능 할 때 주어진 확률을 업데이트 한다. 만약 이러한 확률이 참값으로 확장되고 가설에 할당될 때, 확실성의 가변성에 대한 "학습" 결과를 얻는다.
'Artificial Intelligence > Posts' 카테고리의 다른 글
| [Artificial Intelligence / Posts] 역전파 (Backpropagation) Part 2. (1) | 2017.06.03 |
|---|---|
| [Artificial Intelligence / Posts] 역전파 (Backpropagation) Part 1. (1) | 2017.05.06 |
| [Artificial Intelligence / Posts] R에서의 딥러닝 (0) | 2017.04.20 |
| [Artificial Intelligence / Posts] Machine Learning 분류 (0) | 2017.04.03 |
| [Artificial Intelligence / Posts] 모두가 즐길 수 있는 Deep Learning에 대한 생각 (2) | 2017.03.01 |


