
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- data science
- 김양재 목사님
- 몽고디비
- c++
- 통계
- Artificial Intelligence
- Statistics
- 김양재
- openCV
- nodeJS
- MongoDB
- WebGL
- 인공지능
- No SQL
- 김양재 목사
- node.js
- 빅 데이타
- probability
- R
- 확률
- 주일설교
- Deep learning
- 딥러닝
- 우리들교회
- Machine Learning
- 빅데이타
- 빅 데이터
- 빅데이터
- 데이터 과학
- Big Data
- Today
- Total
Scientific Computing & Data Science
[Artificial Intelligence / Posts] 모두가 즐길 수 있는 Deep Learning에 대한 생각 본문
[Artificial Intelligence / Posts] 모두가 즐길 수 있는 Deep Learning에 대한 생각
cinema4dr12 2017. 3. 1. 20:05모두에게 개방하는 딥러닝
명시적인 프로그래밍을 하지 않고 컴퓨터가 학습하도록 하는 머신러닝은 통상적으로 수학자들과 프로그래머들만이 할 수 있는 마법으로 여겨져 왔다. 한 동안 그래왔는데 그에 대해서는 여러가지 이유가 있다.
코딩을 할 줄 알아야 할뿐더러 강력한 수학적 스킬이 요구되기 때문이다. 돌아갈 방법은 없지만 완전한 수학적 배경없이도 의미있는 많은 일을 할 수 있다.
나는 미래에 우리의 어플리케이션을 보다 스마트하게 만들기 위해 프로그래밍을 하는 우리 모두가 어떤 형태의 딥러닝에 기여하는 과정이라고 믿는다.
피쳐 엔지니어링 (Feature Engineering)
보통 머신러닝을 위해 컴퓨터가 이해할 수 있는 데이터를 컴퓨터에게 공급해야 한다. 이것은 많은 행과 열로 구성되는 대규모의 스프레드시트 형태로 데이터를 변환해야 함을 의미한다. 각 행은 인스턴스 또는 예라고 불리우며 각 열은 피쳐라고 불리운다. 따라서 이들 숫자를 머신러닝에 공급하여 데이터로부터 학습하도록 한다. 피쳐 엔지니어링은 시간이 매우 많이 소요되기 때문에 우리는 시행착오도 많이 해야하고 스마트해야 하며 모델을 향상시키는 피쳐들만을 추출해야 한다. 그러나, 모델을 학습시키고 테스트하기 전까지는 이 피쳐들이 유용한지 알 수 없기 때문에, 새로운 피쳐를 개발하고 모델을 다시 빌드하고 결과를 평가하는 순환과정을 통해 좋은 결과를 얻을 때까지 노력해야 한다. 이 과정은 극도로 많은 시간이 소요되며 대부분의 시간을 소비하게 될 것이다.
딥러닝을 통한 피쳐 추출
딥러닝은 인공신경망(Artificial Neural Network; ANN)의 또다른 이름이다. 이 개념은 40년 이상되었으나, NVIDIA가 과학 컴퓨팅을 위한 칩을 개발하여 비로소 신경망의 붐을 다시 일으켰다. 딥러닝이 "딥"인 것은, ANN의 구조로 인함이다. ANN은 기본적으로 피라미드처럼 쌓인 뉴런의 레이어(Layer)이다. 40년 전에는 신경망은 기껏해야 2개의 레이어뿐이었다. 이는 그 당시에는 더 큰 네트워크 계산을 수행할 수 없었기 때문이다. 즉, 당시 컴퓨팅 파워로는 이것을 계산하는데 몇 달 아니 몇 년이 걸릴 것이기 때문이었다. 이제는 10개 이상의 레이어를 갖는 ANN은 흔한 것이 되었다. 엔지니어들은 100개 이상의 레이어를 갖는 ANN을 생성하기 시작했다.
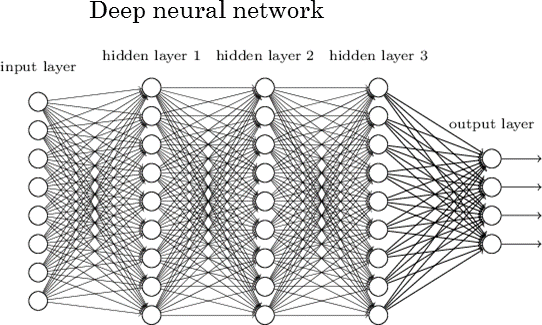
이것이 딥(Deep)이다
뉴런의 레이어를 쌓을 수 있다. 가장 낮은 레이어가 입력 데이터를 받는다: 이미지, 텍스트, 소리 등이며, 각 뉴런은 데이터에 대한 몇몇 정보를 저장한다. 레이어 내의 각 뉴런은 데이터를 더욱 추상적으로 학습하는 다음 레이어의 뉴런으로 정보를 전달한다. 따라서 보다 높은 레이어로 전달될수록 더욱 추상적인 피쳐를 학습하게 된다. 아래의 이미지는 5개의 레이어와 이 중 3개의 은닉 레이어를 볼 수 있다.

심층신경망에서 학습한 피쳐들
그러면 이것이 왜 중요한가? 이느 ANN이 자동으로 피쳐를 추출한다는 것을 의미한다. 이미지를 입력받아 컬러 분포, 이미지 히스토그램, 유일한 컬러 개수 등과 같은 피쳐를 손으로 계산해는 대신 우리는 이미지를 공급만 하면 된다. ANN은 일반적으로 이미지에 대하여 잘 동작했지만 이제는 텍스트와 같은 모든 종류의 다른 데이터세트에도 적용되고 있다. 이것이 게임을 완전히 바꾸어 놓고 있다. 이제 여러분이 머신러닝 모델을 세우고 있다면 알고리즘과 같은 보다 중요한 것에 집중할 수 있다.
오픈 소스와 오픈 사이언스
오픈 소스는 Linux에 정말 감사하고 있다. 매일 하루하루 수많은 오픈 소스 프로젝트들이 생성되고 있다. 또한 다행스럽게도 딥러닝에서 역시 여전히 많은 오픈 소스들이 태어나고 있다. Tensorflow, Torch, keras, Big Sur hardware, DIGITS, Caffe 등은 메이저 오픈 소스 딥러닝 프로젝트들이다. 학계에서는 여전히 많은 논문들이 쏟아져 나오고 있다. 확실히는 모르지만 점점 더욱 많은 논문들이 알고리즘 소스 코드를 포함하고 있다. Arxiv.org는 백만개가 넘는 논문에 대한 접근을 허용하고 있다. 연구가 개방적인 이상 더많은 사람들이 딥러닝 알고리즘을 개발할 것이다.
데이터와 데이터 획득
따라서 더이상 피쳐 엔지니어링을 예전만큼 많이 할 필요가 없게 되었다. 이것은 분명 맞는 말이지만, 학습 알고리즘은 데이터에 굶주려 있으므로 많은 양의 데이터를 모델에 공급해 주어야 할 필요가 있다.
20년 전에는 가질 수 없었던 많은 데이터 소스가 생겨났다. 그것은 인터넷, 위키피디아, 이메일, Flickr, 구글, 프로젝트 구텐베르크등이다. 굉장히 많은 유용한 데이터가 우리에게 있지만 여전히 많은 데이터가 프로세싱을 위해 수집되고 가공되어야 한다. 이것이 우리에게 남겨진 보틀넥이다.
지금으로서는 현실적으로 오직 대기업만이 이러한 머신러닝 모델을 활용할 수 있는 데이터를 수집하고 처리하는 자원을 갖게 될 것이다. 가까운 미래에는 공공 자원으로서 더많은 데이터를 개방하고 공유하게 될 것으로 기대한다. 우리가 새로운 데이터세트를 개방할 때마다 머신러닝의 새로운 벤치마크가 깨어질 것이다.
결론
아직 많은 딥러닝이 광고 단계이지만 충분히 가능성을 보여주고 있다. 점점 더 많은 사람들이 컴퓨터 과학을 공부하고 있으며, 점점 더 많은 사람들이 딥러닝 모델을 만들게 될 것이다. "STEM"을 공부하였거나 프로그래밍을 공부하였다면 여러분은 이미 딥러닝 모델 생성을 위해 필요한 대부분의 스킬을 보유한 것이다. 머신러닝 프레임워크, 더많은 데이터세트에 대한 접근, 더 나은 머신러닝 알고리즘을 개방함으로써 더많은 사람들이 머신러닝에 참여하게 될 것이다. 머신러닝 발전을 더욱 가속화하려면 몇가지 본질적인 작업이 필요하다: 사람들이 머신러닝을 더욱 쉽게 배울 수 있고 사람들이 이용할 수 있는 더나은 소프트웨어를 개발해야 한다. 머신러닝 모델을 개발하는데 조금이라도 관심이 있다면 지금 당장 시작할 것을 권장한다.
'Artificial Intelligence > Posts' 카테고리의 다른 글
| [Artificial Intelligence / Posts] 역전파 (Backpropagation) Part 2. (1) | 2017.06.03 |
|---|---|
| [Artificial Intelligence / Posts] 역전파 (Backpropagation) Part 1. (1) | 2017.05.06 |
| [Artificial Intelligence / Posts] R에서의 딥러닝 (0) | 2017.04.20 |
| [Artificial Intelligence / Posts] Machine Learning 분류 (0) | 2017.04.03 |
| [Artificial Intelligence / Posts] 핵심 머신러닝 용어 (3) | 2017.03.19 |


